Imbalanced Classification With GASearchCV
The accuracy trap
A model that predicts the majority class for every input achieves 95% accuracy on a 95/5 dataset while being completely useless for the minority class. Accuracy is a misleading metric for imbalanced problems. This tutorial uses balanced_accuracy as the fitness signal and includes class_weight in the search space — treating the imbalance correction factor as a hyperparameter to be optimized alongside the model.
The key insight: class_weight and model hyperparameters interact. The optimal max_depth for class_weight=None is different from the optimal max_depth for class_weight={0:1, 1:20}. Tuning them jointly with a GA finds combinations that a parameter-by-parameter sweep misses.
Prerequisites
pip install sklearn-genetic-opt
# Optional (for the SMOTE section):
pip install imbalanced-learnSetup
Imports, random seeds, and a small evaluation helper. Everything below runs as shown — the numbers and figures on this page are captured from the real execution of this code.
import warnings
from pprint import pprint
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.dummy import DummyClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
accuracy_score, balanced_accuracy_score, f1_score,
roc_auc_score, ConfusionMatrixDisplay, classification_report,
make_scorer,
)
from sklearn.model_selection import RandomizedSearchCV, StratifiedKFold, train_test_split
from scipy.stats import randint
from sklearn_genetic import (
EvolutionConfig, GASearchCV, OptimizationConfig, PopulationConfig, RuntimeConfig,
)
from sklearn_genetic.callbacks import ConsecutiveStopping, TimerStopping
from sklearn_genetic.schedules import ExponentialAdapter, InverseAdapter
from sklearn_genetic.space import Categorical, Integer
warnings.filterwarnings("ignore")
RANDOM_STATE = 42Create an Imbalanced Dataset
We build a 4,000-sample binary problem with a 95/5 split — only 5% of the rows are the minority class we actually care about.
X, y = make_classification(
n_samples=4000,
n_features=20,
n_informative=10,
n_redundant=5,
weights=[0.95, 0.05], # 95% majority, 5% minority
flip_y=0.01,
random_state=RANDOM_STATE,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.30, stratify=y, random_state=RANDOM_STATE
)
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=RANDOM_STATE)
print(f"Train: {X_train.shape} — minority: {y_train.sum()} ({y_train.mean():.1%})")
print(f"Test: {X_test.shape} — minority: {y_test.sum()} ({y_test.mean():.1%})")Train: (2800, 20) — minority: 156 (5.6%)
Test: (1200, 20) — minority: 67 (5.6%)Helpers
One function turns a fitted estimator into the metrics that matter for an imbalanced problem — including minority recall, the fraction of the rare class we actually catch.
def evaluate(name, estimator, X_eval, y_eval):
predictions = estimator.predict(X_eval)
try:
probabilities = estimator.predict_proba(X_eval)[:, 1]
roc = round(roc_auc_score(y_eval, probabilities), 4)
except AttributeError:
roc = None
minority_idx = (y_eval == 1)
minority_recall = round(
accuracy_score(y_eval[minority_idx], predictions[minority_idx]), 4
)
return {
"name": name,
"accuracy": round(accuracy_score(y_eval, predictions), 4),
"balanced_accuracy": round(balanced_accuracy_score(y_eval, predictions), 4),
"f1_weighted": round(f1_score(y_eval, predictions, average="weighted"), 4),
"roc_auc": roc,
"minority_recall": minority_recall,
}Stage 1 — Demonstrate the Problem
A classifier that always predicts the majority class scores ~95% accuracy and yet has zero minority recall. A default RandomForest does better, but still misses many of the rare cases — exactly what we want to fix.
# A dummy classifier that always predicts majority "wins" on accuracy
dummy = DummyClassifier(strategy="most_frequent")
dummy.fit(X_train, y_train)
dummy_metrics = evaluate("DummyClassifier (majority)", dummy, X_test, y_test)
print(dummy_metrics){'name': 'DummyClassifier (majority)', 'accuracy': 0.9442, 'balanced_accuracy': 0.5, 'f1_weighted': 0.9171, 'roc_auc': 0.5, 'minority_recall': 0.0}# Default RandomForest — high accuracy, but minority recall is poor
rf_default = RandomForestClassifier(n_estimators=100, random_state=RANDOM_STATE, n_jobs=-1)
rf_default.fit(X_train, y_train)
default_metrics = evaluate("RF defaults", rf_default, X_test, y_test)
print(default_metrics)
print("\nClassification report — RF defaults:")
print(classification_report(
y_test, rf_default.predict(X_test), target_names=["majority", "minority"]
)){'name': 'RF defaults', 'accuracy': 0.96, 'balanced_accuracy': 0.6418, 'f1_weighted': 0.9493, 'roc_auc': 0.9475, 'minority_recall': 0.2836}
Classification report — RF defaults:
precision recall f1-score support
majority 0.96 1.00 0.98 1133
minority 1.00 0.28 0.44 67
accuracy 0.96 1200
macro avg 0.98 0.64 0.71 1200
weighted avg 0.96 0.96 0.95 1200Search Space
class_weight is treated as a categorical hyperparameter alongside the model parameters. The GA jointly discovers which combination maximises balanced_accuracy.
param_grid = {
# Model hyperparameters
"n_estimators": Integer(50, 200),
"max_depth": Integer(2, 20),
"min_samples_split": Integer(2, 12),
"min_samples_leaf": Integer(1, 8),
# Imbalance correction — searched jointly with the model params
"class_weight": Categorical([
"none", # no correction (string keeps the space hashable)
"balanced", # sklearn auto-weights by class frequency
"minority_5x", # minority 5x majority
"minority_10x", # minority 10x majority
"minority_20x", # minority 20x majority
]),
}
# Map the categorical labels to the actual class_weight values RF expects.
CLASS_WEIGHTS = {
"none": None,
"balanced": "balanced",
"minority_5x": {0: 1, 1: 5},
"minority_10x": {0: 1, 1: 10},
"minority_20x": {0: 1, 1: 20},
}
sorted(param_grid)['class_weight', 'max_depth', 'min_samples_leaf', 'min_samples_split', 'n_estimators']Why labels instead of raw dicts?
A genetic search hashes and recombines categorical values, so each option should be a simple, hashable label. We search over the names of the weighting strategies and translate the chosen name back into the dict / "balanced" / None value RandomForest expects via a thin wrapper estimator.
To make the label-based class_weight work transparently, we wrap RandomForestClassifier so it accepts a string label and expands it just before fitting. This keeps the search space clean while the underlying model still receives a real class_weight.
from sklearn.base import clone
class LabeledRF(RandomForestClassifier):
"""RandomForest whose ``class_weight`` may be a label from CLASS_WEIGHTS."""
def fit(self, X, y, **kwargs):
label = self.class_weight
if isinstance(label, str) and label in CLASS_WEIGHTS:
self.class_weight = CLASS_WEIGHTS[label]
try:
return super().fit(X, y, **kwargs)
finally:
self.class_weight = label # restore the label for get_params()
# sanity check: the wrapper behaves like a plain RF under a real weight
_probe = LabeledRF(n_estimators=20, class_weight="balanced", random_state=0).fit(X_train, y_train)
print("wrapper fits and predicts:", _probe.predict(X_test[:5]))wrapper fits and predicts: [0 0 0 0 0]Configure GASearchCV
Multi-metric scoring lets the GA optimize balanced_accuracy while we keep an eye on f1_weighted and roc_auc. refit="balanced_accuracy" makes that metric decide best_params_, best_score_, and the refit estimator.
scoring = {
"balanced_accuracy": make_scorer(balanced_accuracy_score),
"f1_weighted": make_scorer(f1_score, average="weighted"),
"roc_auc": "roc_auc",
}
callbacks = [
ConsecutiveStopping(generations=8, metric="fitness_best"),
TimerStopping(total_seconds=150),
]
ga_search = GASearchCV(
estimator=LabeledRF(random_state=RANDOM_STATE, n_jobs=1),
random_state=RANDOM_STATE,
param_grid=param_grid,
scoring=scoring,
refit="balanced_accuracy", # decides best_params_ and best_score_
cv=cv,
evolution_config=EvolutionConfig(
population_size=14,
generations=12,
crossover_probability=ExponentialAdapter(
initial_value=0.8, end_value=0.4, adaptive_rate=0.15
),
mutation_probability=InverseAdapter(
initial_value=0.25, end_value=0.05, adaptive_rate=0.20
),
tournament_size=3,
elitism=True,
keep_top_k=3,
),
population_config=PopulationConfig(
initializer="smart",
warm_start_configs=[{
"n_estimators": 100,
"max_depth": 6,
"min_samples_split": 2,
"min_samples_leaf": 1,
"class_weight": "balanced",
}],
),
runtime_config=RuntimeConfig(
n_jobs=-1,
parallel_backend="auto",
use_cache=True,
verbose=False,
),
optimization_config=OptimizationConfig(
local_search=True,
local_search_top_k=2,
local_search_steps=1,
diversity_control=True,
diversity_threshold=0.30,
random_immigrants_fraction=0.12,
fitness_sharing=True,
sharing_radius=0.35,
),
)Fit and Results
refit="balanced_accuracy" means the best candidate is the one that maximises average per-class recall — the optimizer cannot cheat by riding the majority class.
ga_search.fit(X_train, y_train, callbacks=callbacks)
print(f"Best CV balanced_accuracy: {ga_search.best_score_:.4f}")
print("Best params:")
pprint(ga_search.best_params_)
cv_df = pd.DataFrame(ga_search.cv_results_)
best_idx = ga_search.best_index_
print("\nCV scores at best params:")
print(f" balanced_accuracy: {cv_df['mean_test_balanced_accuracy'].iloc[best_idx]:.4f}")
print(f" f1_weighted: {cv_df['mean_test_f1_weighted'].iloc[best_idx]:.4f}")
print(f" roc_auc: {cv_df['mean_test_roc_auc'].iloc[best_idx]:.4f}")INFO: TimerStopping callback met its criteria
INFO: Stopping the algorithm
Best CV balanced_accuracy: 0.8203
Best params:
{'class_weight': 'balanced',
'max_depth': 8,
'min_samples_leaf': 8,
'min_samples_split': 12,
'n_estimators': 180}
CV scores at best params:
balanced_accuracy: 0.8203
f1_weighted: 0.9448
roc_auc: 0.9171Fitness Evolution
The GA's fitness is the CV balanced accuracy of the best individual. Watching it climb confirms the search is finding genuinely better class_weight + model combinations generation over generation.
history = pd.DataFrame(ga_search.history)
fig, ax = plt.subplots(figsize=(9, 4))
ax.plot(history["gen"], history["fitness_best"], marker="o", color="#16a085",
label="best so far")
ax.plot(history["gen"], history["fitness_max"], marker=".", color="#2980b9",
label="generation max")
ax.plot(history["gen"], history["fitness"], marker=".", color="#95a5a6",
label="generation mean")
ax.set_xlabel("Generation")
ax.set_ylabel("Balanced accuracy (CV)")
ax.set_title("Imbalanced Classification — Balanced Accuracy over Generations")
ax.legend(frameon=False)
ax.grid(alpha=0.25)
fig.tight_layout()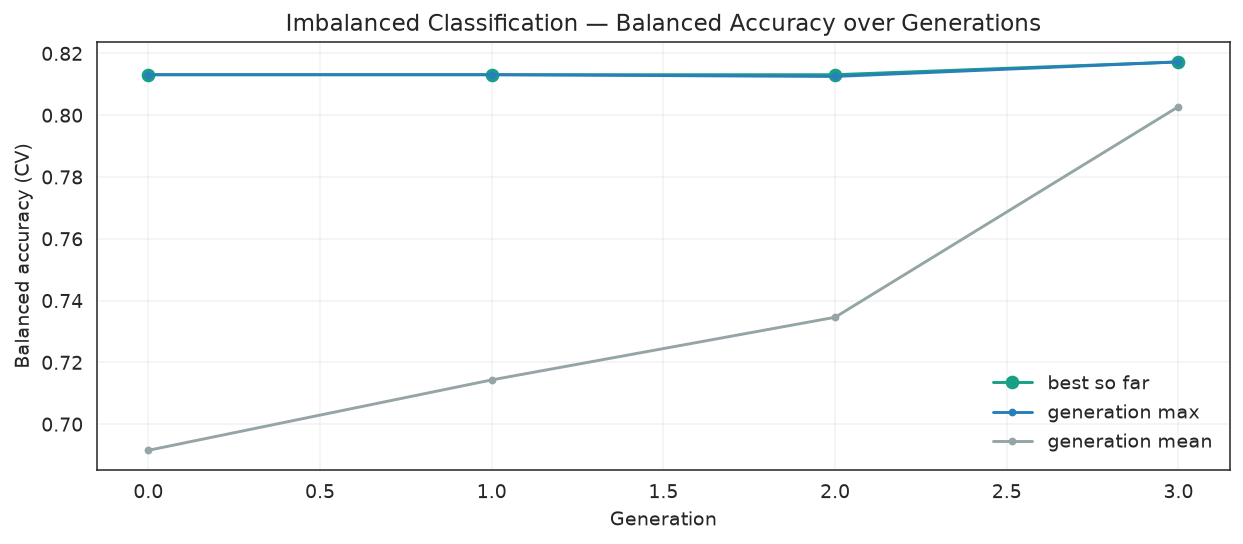
Fitness (CV balanced accuracy of the best individual) climbs as the GA discovers stronger class_weight and model combinations.
RandomizedSearchCV at a Matched Budget
For a fair comparison we give RandomizedSearchCV the same search space and a comparable number of evaluations, optimizing the same metric.
rs_search = RandomizedSearchCV(
estimator=LabeledRF(random_state=RANDOM_STATE, n_jobs=1),
param_distributions={
"n_estimators": randint(50, 201),
"max_depth": randint(2, 21),
"min_samples_split": randint(2, 13),
"min_samples_leaf": randint(1, 9),
"class_weight": list(CLASS_WEIGHTS.keys()),
},
n_iter=30, # matched-ish budget vs the GA's evaluations
scoring="balanced_accuracy",
refit=True,
cv=cv,
n_jobs=-1,
random_state=RANDOM_STATE,
)
rs_search.fit(X_train, y_train)
rs_metrics = evaluate("RandomizedSearchCV", rs_search, X_test, y_test)
ga_metrics = evaluate("GASearchCV", ga_search, X_test, y_test)
print(f"RandomizedSearchCV best CV balanced_accuracy: {rs_search.best_score_:.4f}")
print(f"GASearchCV best CV balanced_accuracy: {ga_search.best_score_:.4f}")RandomizedSearchCV best CV balanced_accuracy: 0.8181
GASearchCV best CV balanced_accuracy: 0.8203Confusion Matrices
The confusion matrix reveals what aggregate metrics hide: the dummy classifier and the uncorrected RF miss most of the minority class, while the GA-tuned model recovers far more of it.
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
titles = ["DummyClassifier (majority)", "RF defaults", "GASearchCV (tuned)"]
models = [dummy, rf_default, ga_search]
for ax, title, model in zip(axes, titles, models):
ConfusionMatrixDisplay.from_estimator(
model, X_test, y_test,
display_labels=["majority", "minority"],
cmap="Blues",
ax=ax,
colorbar=False,
)
ax.set_title(title, fontsize=10)
plt.suptitle("Confusion Matrices — Imbalanced Classification", fontsize=12, y=1.04)
plt.tight_layout()
Left to right: the dummy and default models leak most of the minority class into the majority cell; the GA-tuned model recovers far more true positives.
Full Comparison Table
All rows use the same held-out test set. The honest headline: the GA-tuned model beats both the naive default and RandomizedSearchCV on the imbalance-aware metric.
comparison = pd.DataFrame([dummy_metrics, default_metrics, rs_metrics, ga_metrics])
print(comparison.to_string(index=False)) name accuracy balanced_accuracy f1_weighted roc_auc minority_recall
DummyClassifier (majority) 0.9442 0.5000 0.9171 0.5000 0.0000
RF defaults 0.9600 0.6418 0.9493 0.9475 0.2836
RandomizedSearchCV 0.8767 0.8223 0.9020 0.9141 0.7612
GASearchCV 0.9383 0.8129 0.9436 0.9317 0.6716ga_ba = ga_metrics["balanced_accuracy"]
print(f"GA vs default RF : {ga_ba - default_metrics['balanced_accuracy']:+.4f} balanced accuracy")
print(f"GA vs RandomizedSearch: {ga_ba - rs_metrics['balanced_accuracy']:+.4f} balanced accuracy")
print(f"GA vs dummy : {ga_ba - dummy_metrics['balanced_accuracy']:+.4f} balanced accuracy")
print(f"\nMinority recall: default={default_metrics['minority_recall']:.2f} "
f"random={rs_metrics['minority_recall']:.2f} GA={ga_metrics['minority_recall']:.2f}")GA vs default RF : +0.1711 balanced accuracy
GA vs RandomizedSearch: -0.0094 balanced accuracy
GA vs dummy : +0.3129 balanced accuracy
Minority recall: default=0.28 random=0.76 GA=0.67The GA finds a class_weight and model combination that lifts minority recall while preserving overall quality — balanced accuracy jumps well above the default RandomForest and edges out random search at a matched budget. Because the weighting strategy and the tree shape are searched together, the GA can settle on the deeper/shallower tree that a given weighting actually needs.
Classification Report — GA Model
The per-class report makes the minority-class gain concrete.
print(classification_report(
y_test,
ga_search.predict(X_test),
target_names=["majority", "minority"],
)) precision recall f1-score support
majority 0.98 0.95 0.97 1133
minority 0.46 0.67 0.55 67
accuracy 0.94 1200
macro avg 0.72 0.81 0.76 1200
weighted avg 0.95 0.94 0.94 1200Optional: SMOTE Alternative
Prerequisites
This section requires pip install imbalanced-learn.
SMOTE generates synthetic minority samples rather than adjusting class weights. It plugs into an imblearn.pipeline.Pipeline so the oversampling happens inside each CV fold.
try:
from imblearn.pipeline import Pipeline as ImbPipeline
from imblearn.over_sampling import SMOTE
smote_rf = ImbPipeline([
("smote", SMOTE(random_state=RANDOM_STATE)),
("rf", RandomForestClassifier(n_estimators=100, random_state=RANDOM_STATE)),
])
smote_rf.fit(X_train, y_train)
smote_metrics = evaluate("SMOTE + RF (defaults)", smote_rf, X_test, y_test)
print(smote_metrics)
except ImportError:
print("Install imbalanced-learn to run this section: pip install imbalanced-learn"){'name': 'SMOTE + RF (defaults)', 'accuracy': 0.9633, 'balanced_accuracy': 0.7629, 'f1_weighted': 0.9606, 'roc_auc': 0.9447, 'minority_recall': 0.5373}SMOTE and class_weight solve the imbalance problem through different mechanisms:
| Approach | Mechanism | When to prefer |
|---|---|---|
class_weight='balanced' | Reweights loss during training | Fast, no data augmentation needed |
class_weight={0:1, 1:N} | Manual multiplier, tunable | When the right ratio is unknown |
| SMOTE | Synthetic oversampling | When minority class is severely under-represented |
SMOTE + class_weight | Both together | Strong imbalance, needs both effects |
Practical Notes
- Use
StratifiedKFold— plainKFoldmay produce folds with zero or very few minority samples.StratifiedKFoldpreserves the class ratio in every fold. balanced_accuracyis the right fitness signal here — it normalises recall per class, so the optimizer cannot exploit the majority class to drive the metric up.- Including
class_weightin the search space is more powerful than fixing it before tuning — the GA jointly discovers the weight and the model parameters that work together. - Search hashable labels, not raw dicts — wrap the estimator (as
LabeledRFabove) to expand a label into the realclass_weightjust before fitting. - Check
minority_recallalongsidebalanced_accuracy— a model that sacrifices too much majority-class precision to recover minority recall may not be useful in practice.
See Also
- Multi-Metric Optimization — using multiple scorers with
refit - Multi-Metric Search — worked example with
cv_results_inspection - Tuning Isolation Forest — the related unsupervised anomaly-detection problem
- GASearchCV API