Tuning CatBoost With GASearchCV
CatBoost uses ordered boosting and symmetric trees, which makes its tuning knobs different from XGBoost and LightGBM: depth controls the symmetric tree size, l2_leaf_reg and random_strength regularize, bagging_temperature controls Bayesian bootstrap aggressiveness, and border_count sets the feature-discretization resolution. This tutorial searches that space with GASearchCV and shows the real gain over CatBoost's defaults.
Prerequisites
bash
pip install sklearn-genetic-opt catboostA Noisy Dataset
python
import warnings
import time
import numpy as np
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score, balanced_accuracy_score, roc_auc_score
from sklearn.model_selection import StratifiedKFold, train_test_split
from sklearn_genetic import (
EvolutionConfig,
GASearchCV,
OptimizationConfig,
PopulationConfig,
RuntimeConfig,
)
from sklearn_genetic.callbacks import ConsecutiveStopping, TimerStopping
from sklearn_genetic.schedules import ExponentialAdapter, InverseAdapter
from sklearn_genetic.space import Continuous, Integer
warnings.filterwarnings("ignore")
RANDOM_STATE = 42
X, y = make_classification(
n_samples=2500, n_features=30, n_informative=8, n_redundant=8,
n_clusters_per_class=3, class_sep=0.6, flip_y=0.08, random_state=RANDOM_STATE,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.40, stratify=y, random_state=RANDOM_STATE
)
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=RANDOM_STATE)
print(f"train={X_train.shape} test={X_test.shape}")text
train=(1500, 30) test=(1000, 30)Baseline: CatBoost Defaults
CatBoost manages its own threads; we set thread_count=1 and verbose=0. We cap iterations so the baseline trains quickly.
python
def make_catboost(**kwargs):
params = dict(thread_count=1, verbose=0, random_state=RANDOM_STATE,
allow_writing_files=False)
params.update(kwargs)
return CatBoostClassifier(**params)
def evaluate(name, estimator):
proba = estimator.predict_proba(X_test)[:, 1]
pred = estimator.predict(X_test)
return {
"model": name,
"accuracy": round(accuracy_score(y_test, pred), 4),
"balanced_accuracy": round(balanced_accuracy_score(y_test, pred), 4),
"roc_auc": round(roc_auc_score(y_test, proba), 4),
}
baseline = make_catboost(iterations=300)
baseline.fit(X_train, y_train)
baseline_metrics = evaluate("CatBoost defaults", baseline)
print(baseline_metrics)text
{'model': 'CatBoost defaults', 'accuracy': 0.805, 'balanced_accuracy': 0.8049, 'roc_auc': 0.8803}Search Space
Seven CatBoost-specific parameters. border_count (feature binning resolution) and bagging_temperature (bootstrap aggressiveness) interact with depth and l2_leaf_reg to control over/under-fitting.
python
param_grid = {
"iterations": Integer(100, 350),
"depth": Integer(3, 10),
"learning_rate": Continuous(0.01, 0.3, distribution="log-uniform"),
"l2_leaf_reg": Continuous(1.0, 30.0, distribution="log-uniform"),
"bagging_temperature": Continuous(0.0, 1.0),
"random_strength": Continuous(1e-3, 10.0, distribution="log-uniform"),
"border_count": Integer(32, 255),
}Configure and Run
python
ga_search = GASearchCV(
estimator=make_catboost(),
random_state=RANDOM_STATE,
param_grid=param_grid,
scoring="roc_auc",
cv=cv,
evolution_config=EvolutionConfig(
population_size=10,
generations=8,
crossover_probability=ExponentialAdapter(initial_value=0.8, end_value=0.4, adaptive_rate=0.15),
mutation_probability=InverseAdapter(initial_value=0.25, end_value=0.05, adaptive_rate=0.20),
elitism=True,
keep_top_k=3,
),
population_config=PopulationConfig(
initializer="smart",
warm_start_configs=[{
"iterations": 300, "depth": 6, "learning_rate": 0.1,
"l2_leaf_reg": 3.0, "bagging_temperature": 1.0,
"random_strength": 1.0, "border_count": 254,
}],
),
runtime_config=RuntimeConfig(n_jobs=-1, parallel_backend="cv",
use_cache=True, verbose=False),
optimization_config=OptimizationConfig(
diversity_control=True, fitness_sharing=True,
local_search=True, local_search_top_k=2,
),
)
callbacks = [
ConsecutiveStopping(generations=5, metric="fitness_best"),
TimerStopping(total_seconds=90),
]
started = time.perf_counter()
ga_search.fit(X_train, y_train, callbacks=callbacks)
ga_seconds = time.perf_counter() - started
print(f"Best CV ROC AUC : {ga_search.best_score_:.4f} (search took {ga_seconds:.0f}s)")
print("Best parameters :")
for key, value in ga_search.best_params_.items():
print(f" {key}: {value}")text
INFO: TimerStopping callback met its criteria
INFO: Stopping the algorithm
Best CV ROC AUC : 0.8658 (search took 189s)
Best parameters :
iterations: 225
depth: 9
learning_rate: 0.027578370077838747
l2_leaf_reg: 14.189626805239074
bagging_temperature: 0.9841953273239505
random_strength: 0.01972533036679783
border_count: 196Baseline vs Tuned
python
ga_metrics = evaluate("GASearchCV (tuned)", ga_search)
comparison = pd.DataFrame([baseline_metrics, ga_metrics])
print(comparison.to_string(index=False))
print()
print(f"ROC AUC improvement over defaults: "
f"{ga_metrics['roc_auc'] - baseline_metrics['roc_auc']:+.4f}")text
model accuracy balanced_accuracy roc_auc
CatBoost defaults 0.805 0.8049 0.8803
GASearchCV (tuned) 0.803 0.8029 0.8875
ROC AUC improvement over defaults: +0.0072Fitness over generations
python
import matplotlib.pyplot as plt
history = pd.DataFrame(ga_search.history)
fig, ax = plt.subplots(figsize=(9, 4))
ax.plot(history["gen"], history["fitness_best"], marker="o", label="best so far", color="#8e44ad")
ax.plot(history["gen"], history["fitness"], marker=".", label="generation mean", color="#95a5a6")
ax.set_xlabel("Generation")
ax.set_ylabel("CV ROC AUC")
ax.set_title("CatBoost genetic search — fitness over generations")
ax.legend(frameon=False)
ax.grid(alpha=0.25)
fig.tight_layout()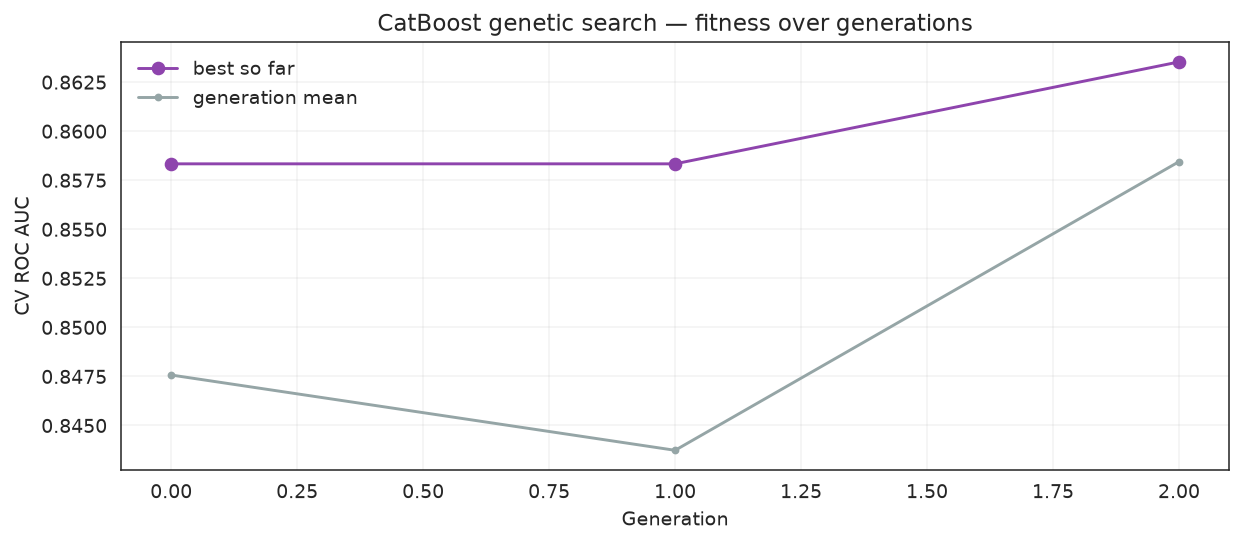
Practical Notes
- Set
allow_writing_files=Falseto stop CatBoost from littering the working directory with training logs. - Pair
thread_count=1withparallel_backend="cv"to avoid CPU oversubscription. border_countrarely needs to exceed 254; higher values cost time for little gain.l2_leaf_regandrandom_strengthare the main regularizers.- The headline win is tuning vs the default model on noisy data.